一、学习要求、重点和难点
本章学习要求:
1、掌握系统误差、偶然(随机)误差的概念和产生原因。掌握误差(绝对误差、相对误差)、偏差(绝对偏差、相对偏差、平均偏差、相对平均偏差、标准偏差、相对标准偏差、平均值的标准偏差)的概念及计算式;
2、掌握准确度与误差的关系、精密度与偏差的关系,准确度与精密度的关系。
3、掌握正态分布、标准正态分布的特点和规律;
4、掌握随机误差区间概率的计算方法和应用。置信度与置信区间的概念和关系(已知总体标准偏差和已知样本标准偏差两种情况);
5、掌握一组数据中可疑值的取舍(Q检验法、G检验法);显著性检验(样本平均值与真值间比较,两组数据间比较)。
6、掌握有效数字的意义和位数确定;有效数字修约规则;有效数字运算规则。
7、了解提高分析结果准确度的方法。
本章的重点:
1、误差是定量分析化学中的基本概念,也是分析化学中的重要的贯穿全书各章的概念,所以要重点理解和掌握其定义以及运算,在实际分析工作中,由于真值未知,一般用测量数据的算术平均值进行计算,所以引入了偏差的定义及计算。
2、数据的统计计算:平均值、标准偏差、相对标准偏差、绝对误差、相对误差的计算等。
3、三种异常值的取舍方法,显著性检验(t检验法和F检验法),平均值的置信区间的求取。
4、有效数字的记录、修约及运算规则。
本章的难点:
1、误差与偏差的区别。误差是表示测量数据与真值之间的差值,偏差表示测量数据与算术平均值之间的差值。
2、系统误差和随机误差的区别。
3、置信度和置信区间的概念和关系。
4、总体和样本的关系;总体和样本的各种统计量的差别。
5、显著性检验的目的和意义。
二、基本术语
1、系统误差与偶然误差
|
|
系统误差(determinate error) |
偶然误差(random error) |
|
概 念 |
因分析过程中某些固定因素造成的误差。对分析结果的影响恒定,具有重现性,或偏高或偏低,可预测性。 |
由不定因素引起的,可变的,时大时小,时正时负。又称随机误差。 |
|
产生原因 |
方法误差、仪器误差、试剂误差、主观误差 |
偶然的因素(定量分析中外界条件的改变及工作中难于估计的因素) |
|
特 点 |
恒定性、单向性、重现性 |
不恒定、难以校正,服从正态分布 |
|
减免方法 |
对照试验、空白试验和校正仪器 |
增加平行测定次数 |
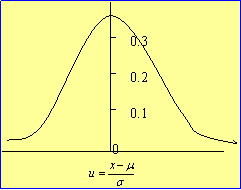 多次测定的偶然误差遵循正态分布规律。正态分布曲线的纵坐标代表相对频数,横坐标代表随机误差的值(x-μ)/σ,这种正态分布曲线称为标准正态分布曲线。如图。
多次测定的偶然误差遵循正态分布规律。正态分布曲线的纵坐标代表相对频数,横坐标代表随机误差的值(x-μ)/σ,这种正态分布曲线称为标准正态分布曲线。如图。
偶然误差存在如下规律:
1)对称性:正负误差出现的几率相等。
2)单峰性:小误差出现的几率大,大误差出现的几率小。误差分布曲线只有一个峰值,有明显的集中趋势。
3)有界性:很大的误差出现的几率几乎为零;也就是说误差值有一定的实际极限。
4)抵偿性:误差的算术平均值的极限为零。
2、误差和偏差
1)误差:分析结果和真实值之间的差值称为误差。
2)偏差:指个别测定值xi与几次测定值的平均值x 之间的差别。
3、真值、平均值和中位数
1)真值(xT):某一物理量本身具有的客观存在的真实数值。有理论真值;计量学约定真值;相对真值。
2)平均值(![]() );n次测量数据的算术平均值。
);n次测量数据的算术平均值。
![]()
3)中位数(xM):一组测量数据按大小顺序排列,中间一个数据即为中位数xM。当测量数据为偶数时,中位数为中间相邻两个测量值的平均值。
4、准确度与精密度
1)准确度(accuracy)是指测定结果的平均值与真值接近程度,常用误差大小表示。误差小,准确度高。
2)精密度(precision)是指在确定条件下,平行测定多次,所得结果之间的一致程度。精密度的大小常用偏差表示。
3)准确度与精密度的关系:准确度好的结果要求精密度好,精密度好的结果准确度不一定好。所以,有好的精密度才可能有好的准确度。
5、重复性与再现性
1)重复性repeatability):同一操作者,在相同条件下,获得一系列结果之间的一致程度
2)再现性(reproducibility):不同操作者,在不同条件下,用相同的方法获得单个结果之间的一致程度。
6、正态分布、标准正态分布与t分布
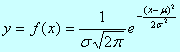
 1)正态分布:又称高斯分布图。
1)正态分布:又称高斯分布图。
(1)
μ和σ确定后,正态分布曲线的位置和形状也就确定了。因此μ和σ是正态分布的两个基本参数,正态分布可用N(μ,σ2)
2)标准正态分布:
若将正态分布的横坐标用u表示(以为单位表示随机误差)
![]()
u为标准正态变量,此时式(1)变为只有变量u的函数表达式
经上述变换后,总体平均值为μ,总体标准偏差为σ的任一正态分布均可转换为μ =0,σ2 =1的标准正态分布,以N(0,1)表示。曲线的形状与μ和σ无关。
3)t分布:
实际工作中,有限次测定无法得知μ和σ,只能求![]() 和S。而当测定次数有限时,测定值或随机误差也不符合正态布,而是符合t 分布。
和S。而当测定次数有限时,测定值或随机误差也不符合正态布,而是符合t 分布。
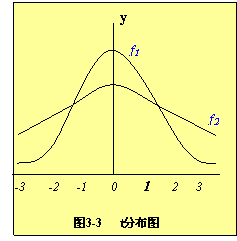 tp,f 是随置信度P和自由度 f 而变化的统计量。t 分布曲线的形状随 f ( f = n-1 )而变化。
tp,f 是随置信度P和自由度 f 而变化的统计量。t 分布曲线的形状随 f ( f = n-1 )而变化。
与正态分布曲线一样,t 分布曲线下面某区间的面积也表示随机误差在此区间的概率。但 t 值与标准正态分布不同,它不仅与概率还与测定次数有关。
7、置信度与置信区间
1)置信度或置信水平:某一定范围的测定值(或误差值)出现的概率
2)置信区间:真实值在指定的概率下,分布的某一个区间。
置信度高,置信区间就宽。
8、有效数字
有效数字:既表示测量数值大小,又能正确反映测量数据精确程度的数,称之为有效数字。
三、基本公式和运算
1、误差(error)
1)绝对误差 ![]()
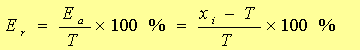 2)相对误差
2)相对误差
对于多次测定,结果的平均值为![]() 。
。
2、偏差(deviation)
![]() 1)单个数据:
1)单个数据:
①绝对偏差di :
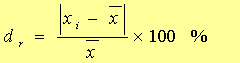 |
②相对偏差dr:
绝对误差和相对误差都有正负,正值表示分析结果偏高,反之偏低。实际工作中,真值并不知道,常把多次测定结果的平均值看作真值。
2)单次测定数据(一组数据)
①算术平均偏差di:一组数据中各个偏差的绝对值的平均值
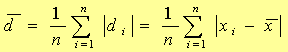 |
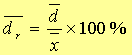 ②相对算术平均偏差
②相对算术平均偏差![]() :
:
可以用平均偏差表示一组数据的精密度。但它反映不出少数大偏差测定值的影响。使其存在一定局限性。
3)统计学中偏差表示
当n为无限大时,设μ为无限次测定结果的平均值,也称总体平均值。
①总体标准偏差(均方根偏差):
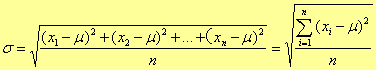
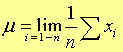

对于一组具体的数据,n是有限的。
②标准偏差(S):
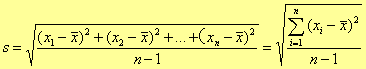 |
|||
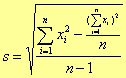 |
|||
或:
式中 n-1 称为自由度,是指独个变量的个数。
平均偏差与标准偏差相比,前者计算简便,但标准偏差能更好地反映出小或大的偏差,能更清楚地说明数据分散程度。
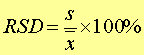 ③相对标准或偏差变异系数(RSD或CV):
③相对标准或偏差变异系数(RSD或CV):
4)平均值的标准偏差
如对同一样品测定了n 组数据,由此可得到n个平均值,这些平均值间的差别,可用平均值的标准偏差表示。
①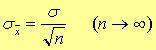 对于无限次测定:
对于无限次测定:
②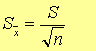 对于有限次测定:
对于有限次测定:
增加测定次数可以减小测定值的偏差,提高测定的精密度。
3、随机误差的区间概率
图3-4所对应的区间概率总和为100%,即为1。
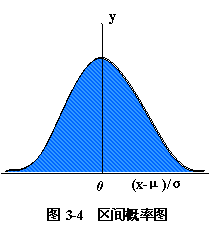
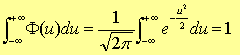
则随机误差在±σ区间(u= ± 1),即测定值在μ±σ区间出现的概率是:
|
随机误差出现区间 |
测定值出现的区间 |
概 率 |
|
u=±1 |
x=μ±σ |
0.6826 |
|
u=±2 |
x=μ±2σ |
0.9548 |
|
u=±3 |
x=μ±3σ |
0.9974 |
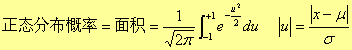
4、置信度与μ的置信区间
随机误差的分布规律表明,测定值总是在以为μ中心的一定范围内波动,并有着向μ集中的趋势。如何根据有限的测定结果来估计μ可能存在的范围(称为置信区间)该范围越小,说明测定值与μ愈接近,即测定的准确度愈高。但由于测定次数一般较少,由此计算出的置信区间也不可能有100% 把握将μ包括在内,只能以一定的概率(置信度)进行判断。
置信度或置信水平—某一定范围的测定值(或误差值)出现的概率
置信区间—真实值在指定的概率下,分布的某一个区间。
如真值在95.5%的概率下出现的范围(置信区间)为μ±2σ。
置信度高,置信区间就宽。
1)己知总体标准偏差σ时
![]() 由于平均值较单次测定值的精密度更高,因此常用样本平均值
由于平均值较单次测定值的精密度更高,因此常用样本平均值![]() 来估计真值所在的范围。
来估计真值所在的范围。
![]() 上两式分别表示在一定置信度时,以单次测定值x或以平均值
上两式分别表示在一定置信度时,以单次测定值x或以平均值 ![]() 为中心的包含真值μ的取值范围,即μ的置信区间。在置信区间内包含μ的概率称为置信度,它表明对所作判断有把握的程度,用 P 表示。
为中心的包含真值μ的取值范围,即μ的置信区间。在置信区间内包含μ的概率称为置信度,它表明对所作判断有把握的程度,用 P 表示。
2)己知样本标准偏差S时
实际工作中,有限次测定无法得知μ和σ,只能求x和S。而当测定次数有限时,测定值或随机误差也不符合正态布,而是符合t 分布。
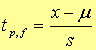 |
tp,f 是随置信度P和自由度 f 而变化的统计量。t 分布曲线的形状随 f ( f = n-1 )而变化。
与正态分布曲线一样,t 分布曲线下面某区间的面积也表示随机误差在此区间的概率。但 t 值与标准正态分布不同,它不仅与概率还与测定次数有关。
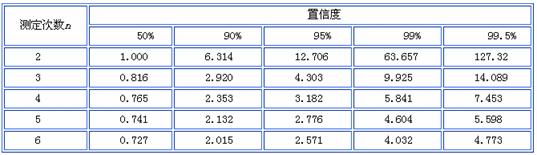
不同 P 和 n 对应的 t 值见表 3-2.
表3-2 t 值表 (t. 某一置信度下的几率系数)
![]()
![]()

或:
上式是计算有限次测定,置信区间公式。当P一定时,置信区间的大小与tp,f、s 和n有关,且tp,f和 s实际也受n的影响,即n 值越大,置信区间越小。
5、可疑测定值的取舍
1)Q 检验法
于1951年由迪安(Dean)和犾克逊(Dixon)提出。
基本步骤:
(1) 数据排列 X1 X2 …… Xn
(2) 确定可疑值: X1 或 Xn (一般是极值)
(3) 求极差 Xn - X1
(4) 求可疑数据与相邻数据之差 Xn - Xn-1 或 X2 -X1
![]() (5) 计算:
(5) 计算:
(6) 根据测定次数和要求的置信度,(如90%)查表:
(7) 将Q计与Q表 (如 Q90 )相比,
若Q计> Q表 舍弃该数据, (过失误差造成)
若Q计 < Q表 保留该数据, (偶然误差所致)
当数据较少时舍去一个后,应补加一个数据。
表3-3 不同置信度下,舍弃可疑数据的Q值表
|
测定次数 |
Q90 |
Q95 |
Q99 |
|
3 |
0.94 |
0.98 |
0.99 |
|
4 |
0.76 |
0.85 |
0.93 |
|
8 |
0.47 |
0.54 |
0.63 |
2)格鲁布斯(Grubbs)检验法
基本步骤:
(1)排序:X1, X2, X3, X4……Xn
![]() (2)求X和标准偏差S
(2)求X和标准偏差S
(3)设X1 或Xn为可疑值,计算G值:
(4)由测定次数和要求的置信度,查表得G表
(5)比较:若 G计算> G表,弃去可疑值,反之保留。
由于格鲁布斯(Grubbs)检验法引入了标准偏差,故准确性比Q 检验法高。
表3-4 G值表
|
n |
置信度(P) |
||
|
95% |
97.5% |
99% |
|
|
3 4 5 6 7 8 9 10 11 12 20 |
1.15 1.46 1.67 1.82 1.94 2.03 2.11 2.18 2.23 2.29 2.56 |
1.15 1.48 1.71 1.89 2.02 2.13 2.21 2.29 2.36 2.41 2.71 |
1.15 1.49 1.75 1.94 2.10 2.22 2.32 2.41 2.48 2.55 2.88 |
3)四倍法
基本步骤:
(1) 确定可疑值 Xi 。
(2) 先计算 (不包括可疑值)的其它数据的平均值(X)和平均偏差(d)。
(3) 计算出可疑值与平均值之差(Xi – X )。
![]() (4)
(4)
如果上式≥4,可疑值(Xi )就应弃去,反之应予以保留。此法适用每组4~8个数据的数据组
6、显著性检验
1)平均值与标准值(m)的比较(t检验法)
为检验一个分析方法是否可靠?是否有足够的准确度?常用已知含量的标准试样进行试验,用t 检验法将测定的平均值与已知值(标样值)比较计算出t值,再与t表进行比较,从而来判断方法是否可靠。
主要步骤为:首先计算![]() 及s;然后计算
及s;然后计算![]() 或者
或者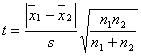 ;最后比较t与tα,f,若t > tα,f
,则存在系统误差;若 t ≤ tα,f ,则不存在系统误差。
;最后比较t与tα,f,若t > tα,f
,则存在系统误差;若 t ≤ tα,f ,则不存在系统误差。
2)两组数据的平均值比较(同一试样)
当需要对两个分析人员测定相同试样的结果进行评价,或需对两种方法进行比较,检验两种方法是否存在显著性差异?即是否有系统误差存在?也可选用t 检验法进行判断。
方 法:
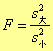 |
(1)首先判断两组数据的精密度是否有较大的差别,用F检验法。又称方差比检验:
S大和S小 分别代表两组数据中标准偏差大的和小的数值。
若:F计算 < F表,再继续用t 检验法判断x1与x2是否有显著性差异 ;
若:F计算 > F表,说明这两组数据的精密度存在显著性差异,其准确度值得怀疑,不必再对两个平均值进行比较。F表见表3-5。
(2)求两组数据合并后的标准偏差:
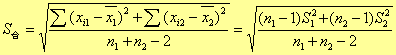 |
||
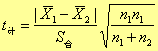 |
||
(3)计算t值:
(4)查表3-2,得t表,比较:
若:t计 > t表,表示两组数据间存在显著性差异;
t计 < t表 两组数据间没有显著性差异。
表3-5 置信度为95%时F值
|
fs大 fs小 |
2 |
3 |
4 |
5 |
6 |
7 |
∞ |
|
2 3 4 5 6 7 ∞ |
19.00 9.55 6.94 5.79 5.14 4.74 3.00 |
19.16 9.28 6.59 5.41 4.76 4.35 2.60 |
19.25 9.12 6.39 5.19 4.53 4.12 2.37 |
19.30 9.01 6.26 5.05 4.39 3.97 2.21 |
19.33 8.94 6.16 4.95 4.28 3.87 2.10 |
19.36 8.88 6.09 4.88 4.21 3.79 2.01 |
19.50 8.53 5.63 4.36 3.67 3.23 1.00 |
7. 有效数字及其运算规则
1)有效数字概念:
2)有效数字记录。分析数据记录时,要根据分析方法和测量仪器的精度来决定数据的有效数字位数。记录的数据中只有最后一位是可疑的。pH,pK等对数表示的数据,其有效数字取决于小数部分数字的位数。
3)有效数字的修约原则。对分析数据进行处理时,要按照“四舍六入五留双”的规则合理保留各步计算中的有效数字位数。
4)有效数字的运算规则。分析数据计算时,对数据要先修约再计算。
加减法运算中,以小数点后位数最少的(即绝对误差最大的)那个数为根据,来修约其他各个数据的位数,然后再计算。
乘除法运算中,以有效数字位数最少的(即相对误差最大的)那个数为根据,来修约其他各个数据的位数,然后再计算。